Wait, when was the last time you blogged?
Since my last post, I took a new position at California State University, Fullerton, got tenure, became vice-chair of the department, had to give up homeschooling my three boys, coached a tremendous amount of Little League, and ran my first marathon. I’ve also gone from being an enthusiastic (maybe even avid) gamer to a certified hobbyist (read “nutjob”). My gaming collection far exceeds 300 games, with some number of expansions in the triple digits. But you didn’t come here to read me bragging about my game collection—if you did, then you should come over and play some games with me. You came for the kind of insightful commentary you read over at dy/dan or Solvable by Radicals. Well, I might be a touch out of practice to reach those levels.
Why blog again?
I’m going to assume you aren’t asking that question as a way of passive-aggressively suggesting that you were quite happy with me not blogging and that you would prefer I had kept my keyboard shut. Instead, I am going to assume that you are genuinely curious as to why a successful (some would say amazing) professor and father, who has achieved all conceivable forms of academic and personal success, would feel the need to say anything to the math edu-blog-o-sphere (is that still a thing?). The answer is simple: a promise.
A little dramatic isn’t it?
Yeah, well, a big change requires something drastic, right? In this case, though, the something drastic was a not-so-chance meeting with Bret Benesh at the MAA MathFest in Cin City. For those of you who don’t follow the comment section of Bret’s blog, I’ve been a long-time reader and occasional responder to Solvable by Radicals. Over the years, we have communicated via blog comment section and even a few times by email, but we had never met in person. When I saw that Bret was planning to go to MathFest, I immediately commented on his blog that I would be going. Naturally, he didn’t see it before the conference, but amazingly he saw my name in the program and sought out my joint talk with colleague Matt Rathbun (I’ll describe the talk in my next post). After the talk he found me, and then I got to have a fun conversation over lunch with Bret and his super cool patient wife, along with Matt and another new friend and CSUF alum Michael Martinez. Recently, Bret started blogging again after a hiatus and the world is a much better place because of it. He encouraged me to start again, and, well, I promised that I would write a blog post on the airplane ride home. And you don’t break your promises to your heroes!
So, do you actually have anything to say?
Wouldn’t you like to know?
Yes. that is why I asked, and why I am reading your blog.
Hmmm…you called my bluff. Here’s the deal. I’ve done a lot over the past seven years and some of it might even be worth mentioning. Let’s keep this stuff compartmentalized, though. This blog post fulfills the promise. The next one will get into some real thoughts on—well, anything I find relevant. The good news for me is that I am clever enough to be able to connect to my work to anything in which I’m interested, and not so clever as to realize when I’ve jumped the shark.
Fun fact: Students today are more likely to know the phrase “jump the shark” than to have any clue as to its etymology.
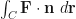 , I thought, “Why should that dot product be in there. By the time I saw
, I thought, “Why should that dot product be in there. By the time I saw 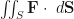 , I resigned myself to the fact that there was always a dot product in these seemingly random integrals. At some point, I decided that the dot products are in there to turn vectors (or vector fields) into scalar functions—which is something we know how to integrate. More recently, I’ve decided that the purpose of these dot products is to capture the projection of one vector on the other.
, I resigned myself to the fact that there was always a dot product in these seemingly random integrals. At some point, I decided that the dot products are in there to turn vectors (or vector fields) into scalar functions—which is something we know how to integrate. More recently, I’ve decided that the purpose of these dot products is to capture the projection of one vector on the other. to an object, then the work done by that force in moving the object a certain distance in a given direction (denote this shift by
to an object, then the work done by that force in moving the object a certain distance in a given direction (denote this shift by  ) is
) is  . If the force is not constant over some curve parametrized by
. If the force is not constant over some curve parametrized by  (
(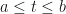 ), then we compute the work by evaluating the integral
), then we compute the work by evaluating the integral 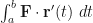 since, at any given point, our
since, at any given point, our 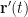 .
.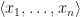 and
and 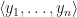 is
is 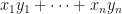 .
. and
and 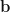 be vectors with angle
be vectors with angle 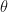 between them, then
between them, then 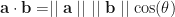 .
.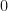 .
.



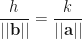 . Ugh, let’s clear denominators to get
. Ugh, let’s clear denominators to get 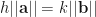 . On the other hand,
. On the other hand, 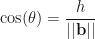 , and so if we multiply by
, and so if we multiply by 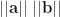 , we get
, we get
 which only relies on knowing the original vectors and the angle between them. Since this projection property is so important to us physically, we give a short name to this expression:
which only relies on knowing the original vectors and the angle between them. Since this projection property is so important to us physically, we give a short name to this expression: 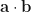 , and call it the dot product of
, and call it the dot product of  is
is ![y = \sqrt[3]{\dfrac{(3x-2)^2\sqrt{2x^3+1}}{x^4(x-1)}}](https://s0.wp.com/latex.php?latex=y+%3D+%5Csqrt%5B3%5D%7B%5Cdfrac%7B%283x-2%29%5E2%5Csqrt%7B2x%5E3%2B1%7D%7D%7Bx%5E4%28x-1%29%7D%7D&bg=ffffff&fg=111111&s=0&c=20201002)
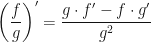

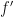 should have a positive sign in front of it. Similarly, if the derivative of the denominator is increasing, then the denominator is getting bigger faster, which means the quotient is getting smaller faster, and so the derivative of the quotient is decreasing, i.e.,
should have a positive sign in front of it. Similarly, if the derivative of the denominator is increasing, then the denominator is getting bigger faster, which means the quotient is getting smaller faster, and so the derivative of the quotient is decreasing, i.e., 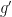 should have a negative sign in front of it.
should have a negative sign in front of it.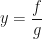 , then
, then 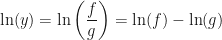 . Differentiating both sides using the chain rule yields
. Differentiating both sides using the chain rule yields
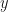 . This is one of my favorite exercises to give first year calculus students—before and after teaching them logarithmic differentiation*.
. This is one of my favorite exercises to give first year calculus students—before and after teaching them logarithmic differentiation*.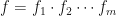 and that
and that 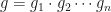 . Setting
. Setting 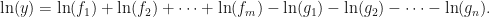
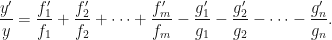
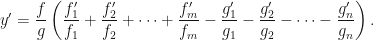
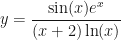 . The usual way would involve the quotient rule mixed with two applications of the product rule. The alternative is to simply rewrite the function, and to work term by term giving:
. The usual way would involve the quotient rule mixed with two applications of the product rule. The alternative is to simply rewrite the function, and to work term by term giving: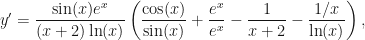
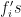 and
and 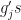 has an exponent, call them
has an exponent, call them 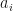 and
and 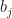 , respectively. In this case, using logarithmic differentiation, we get:
, respectively. In this case, using logarithmic differentiation, we get: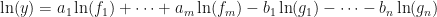 .
.
 .
.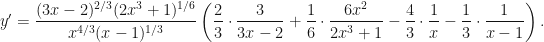
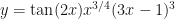 . Normally, one would use the product rule here, but why don’t we try our formula. It gives:
. Normally, one would use the product rule here, but why don’t we try our formula. It gives: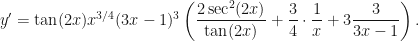
 so as to avoid unnecessary constants when differentiating (recall that when
so as to avoid unnecessary constants when differentiating (recall that when  is a function of
is a function of  that
that  —then we can deconstruct the right hand side using the log rules to get:
—then we can deconstruct the right hand side using the log rules to get:![\ln(y) = \dfrac{1}{3}\left[2\ln(3x-2) + \frac{1}{2}\ln(2x^3 + 1) - 4\ln(x) - \ln(x-1)\right]](https://s0.wp.com/latex.php?latex=%5Cln%28y%29+%3D+%5Cdfrac%7B1%7D%7B3%7D%5Cleft%5B2%5Cln%283x-2%29+%2B+%5Cfrac%7B1%7D%7B2%7D%5Cln%282x%5E3+%2B+1%29+-+4%5Cln%28x%29+-+%5Cln%28x-1%29%5Cright%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
.![\dfrac{1}{y}\dfrac{dy}{dx} = \dfrac{1}{3}\left[\dfrac{2\cdot 3}{3x-2} + \dfrac{6x^2}{2(2x^3+1)} - \dfrac{4}{x} - \dfrac{1}{x-1}\right]](https://s0.wp.com/latex.php?latex=%5Cdfrac%7B1%7D%7By%7D%5Cdfrac%7Bdy%7D%7Bdx%7D+%3D+%5Cdfrac%7B1%7D%7B3%7D%5Cleft%5B%5Cdfrac%7B2%5Ccdot+3%7D%7B3x-2%7D+%2B+%5Cdfrac%7B6x%5E2%7D%7B2%282x%5E3%2B1%29%7D+-+%5Cdfrac%7B4%7D%7Bx%7D+-+%5Cdfrac%7B1%7D%7Bx-1%7D%5Cright%5D&bg=ffffff&fg=111111&s=0&c=20201002) .
. .
.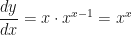 .
.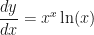 .
.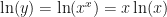 .
. .
.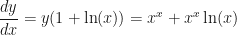 , the sum of the two incorrect answers.
, the sum of the two incorrect answers. , we can get a general rule which is not particularly well-known:
, we can get a general rule which is not particularly well-known: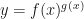 is differentiable, then
is differentiable, then  , i.e., evaluate the derivative using the power and chain rules, then with the exponential and chain rules, and finally add the two incorrect answers together.
, i.e., evaluate the derivative using the power and chain rules, then with the exponential and chain rules, and finally add the two incorrect answers together.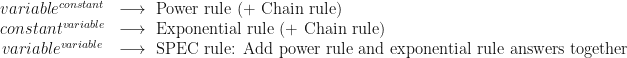
![y = [\sin(x)]^x](https://s0.wp.com/latex.php?latex=y+%3D+%5B%5Csin%28x%29%5D%5Ex&bg=ffffff&fg=111111&s=0&c=20201002) . The SPEC rule makes this a piece of cake: the power rule gives
. The SPEC rule makes this a piece of cake: the power rule gives 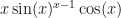 and the exponential rule gives
and the exponential rule gives  . Adding them together gives:
. Adding them together gives: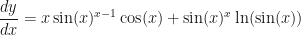 .
.